浅谈 Git
前言
随着世界的扁平化,团队的合作已经不再局限于地理位置,集中式的开发模式在向分布式转变,git就是在这种背景下出现的优秀版本管理工具。它为开源社区、大型项目开发等团队合作带来很大便利。今天这篇文章我想聊聊关于git命令以外的那些事,所以在阅读本文时,你需要了解git一些简单的命令,最好有使用经验,当然如果你已经是个git高手,可以忽略下面的内容。
1. Git分布式版本控制系统(DVCS)
如果你之前使用过Subversion(SVN)这样的集中式版本控制系统,我想你一定抱怨过因为服务器无法连接而耽误你的工作。而git它完全抛弃了以服务器为中心的理念,只要你使用git clone这个命令,你就可以在本地获得整个版本仓库(local repository),这样即使在没有网络的情况下,你也可以随时查看(git log)以往的记录并且提交(git commit)你的代码。一旦网络恢复你可以再次连上远程版本库(remote repository),同步(git fetch)其他同事提交的代码并合并(git merge)自己的代码,然后提交(git push)到远程仓库。作为分布式系统,它并没有一个完全意义上的中心服务器的概念,任何一个本地仓库都可以作为coordinator或服务器。
2. Git的基本概念
git作为一个版本控制系统,它的大部分命令都会涉及到文件状态和操作区域,下面我们来了解下这些概念:
-
工作区(Working Directory)
工作区顾名思义就是我们编辑(添加、修改、删除)文件的地方。通过
git init我们可以将当前文件夹设置成工作区,在这个目录下的文件或文件夹(除.git文件夹以外)一般有三种状态unmodified(文件在本地仓库已经有记录,而且并没有在工作区中被修改过)、untracked(工作区中新添加或删除的文件,这些在本地仓库中并没有记录)、modified(本地仓库已经记录,但在工作区中已经被编辑过),我们在工作区的操作就是在改变文件的这三种状态。 -
暂存区(Staging Area/Index)
暂存区有时也叫Index,本质上它是一个准备提交文件的缓存区,我们可以将工作区的编辑
git add到暂存区,然后git commit最终修改到本地仓库。为什么需要一个暂存区,理由其实和回收站很类似——为我们的误操作提供补救的机会。当然git给暂存区提供了更强大的功能。我们还可以通过暂存区保存一个临时版本,然后继续在工作区编辑,这样我们可以方便地git diff暂存区和工作区的差异,最后决定提交(git commit)哪个版本。所有处于untracked或者modified状态的文件都可以通过git add命令将其快照保存到暂存区使文件变成staged状态。 -
本地仓库(Local Repository)
本地仓库就是最终保存文件版本数据的地方,文件一旦被
git commit到本地仓库,那么所有的操作历史都会被记录下来。我们可以git log任何时候的代码,即使一些文件在某些版本已经被删除。通过git commit命令所有staged状态的文件都会变成unmodified。因为有了本地仓库,所以我们可以在离线的状态下随心所欲的提交代码以及查看之前的版本记录。 -
远程仓库(Remote Repository)
远程仓库顾名思义网络另一端的仓库,本质上远程仓库和本地仓库是一模一样的,这里的区别只是我们在逻辑上给它定义的角色。很多时候我们需要共享彼此的代码或集中式的管理,我们可以通过
git fetch或者git pull来获取远程的代码。同样我们也可以通过git push将本地仓库的代码提交到远程仓库。下图描述了工作区、暂存区、本地仓库、远程仓库与命令之间的关系:
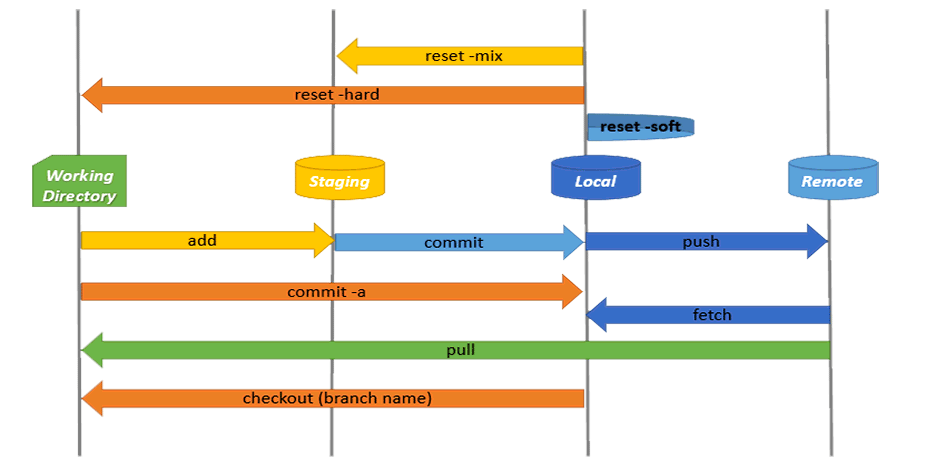
在了解了上述概念后,我们再来看下对应的物理存储吧。在我们用git init命令后,git会在工作目录中新添加了一个.git文件夹。下面就是.git文件夹的目录结构
../
./
config
#项目特有的配置信息
description
#GitWeb使用
HEAD
hooks/
#为git定制一些脚本,让它在某些命令后被git调用
index
info/
#里面有一个exclude文件,功能和.gitignore类似
logs/
#日志信息
objects/
refs/
下面我们重点介绍以下几个文件和文件夹。
-
HEAD文件
git有一个HEAD指针概念,每个分支都有一个HEAD指针指向当前分支的最新版本。这个文件就是记录当前checkout的分支,打开HEAD文件里面会有类似
ref: refs/heads/developer的内容,它表示当前checkout的是developer分支,并且告诉你获取分支的最新版本路径。在refs/heads/developer文件中保存了一个40位的SHA-1值71fafd489cdafdd54d504d6eb282ced1a2c5fa5e,它就是此分支的最新版本号。我们可以通过git log 71fafd489cdafdd54d504d6eb282ced1a2c5fa5e获得这个版本的日志信息。 -
refs目录
这个目录不仅包含各个分支(包括本地和远程)的HEAD版本号,而且还保存了每个tag的版本号以及stash文件等。我们可以把它理解为指针的地址,通过这些地址我们可以获取版本数据。
-
objects目录
../ ./ pack/ info/ 71/ fafd489cdafdd54d504d6eb282ced1a2c5fa5e之所以把objects文件夹的具体结构列出来,是因为objects目录是git最重要的目录,它里面包含了所有提交的数据信息。git会在每次版本提交时根据提交的内容生成一个40位的SHA-1值作为版本号,然后以此版本号的前2位生成一个目录,并将提交的内容(Commit Object我们会在后面进行介绍)保存到以后38位命名的文件中。随着objects目录里面的文件夹越来越多,我们可以通过
git pack-objects来打包这些数据。在我们第一次git clone一个代码库时,git会在objects的pack目录下生成一个.pack和.idx文件。我们可以用git unpack-objects来解压缩,获取上述目录结构。 -
index
index文件保存了暂存区中相关文件的元信息、提交对象的SHA-1值以及一些扩展信息等。在此澄清一点,index文件并没有包括所有提交数据的快照,具体数据还是保存在objects目录下。
3. 提交对象(Commit Object)
前面我们提到每个提交都会生成一个提交对象。下面我们看看提交对象的结构:
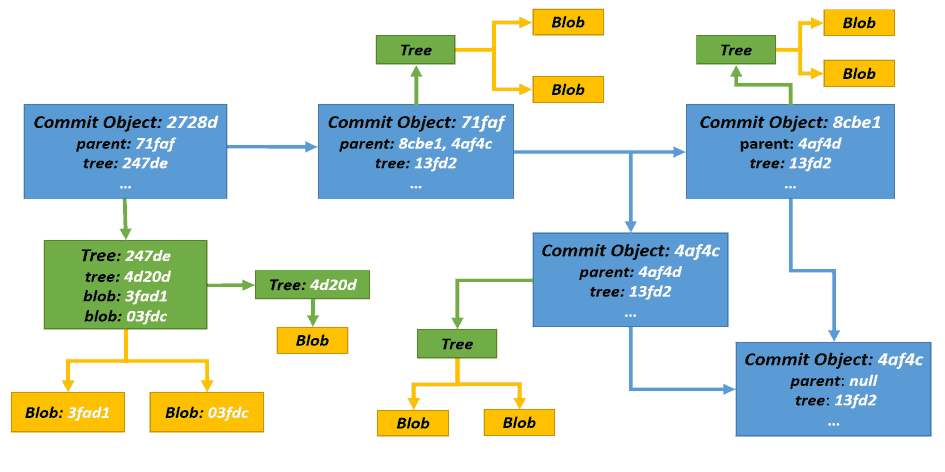
上面总共有三种类型的对象:Commit Object,Tree Object和Blob Object。
Commit Object:每个版本提交的基本单位,它不仅包含提交对象的元信息,而且还包含Tree对象的引用、以及它所依赖的前版本的引用。就像链表一样,我们可以根据当前的提交对象找到之前所有提交的版本信息。前面提到的HEAD指针,其实就是指向具体Commit Object的SHA-1值。
Tree Object:就像文件目录,它将多个文件组织到一起。通过Tree对象,我们可以查到它所包含的Blob对象以及其它子树对象。
Blob Object:保存具体版本数据的对象。它包含所有文件的快照索引,没有修改的文件则保留一个指向前一个版本的链接。
以上所有对象多被保存在objects目录的子文件夹中。
4. 分支(Git Branch)
分支在版本控制系统中的重要性不言而喻,我们可以根据不同的目的建立不同的分支,这样不仅便于管理,而且可以避免非相关提交的相互影响。git可以用git branch命令快速的建立一个分支,下面我们先看一张图:
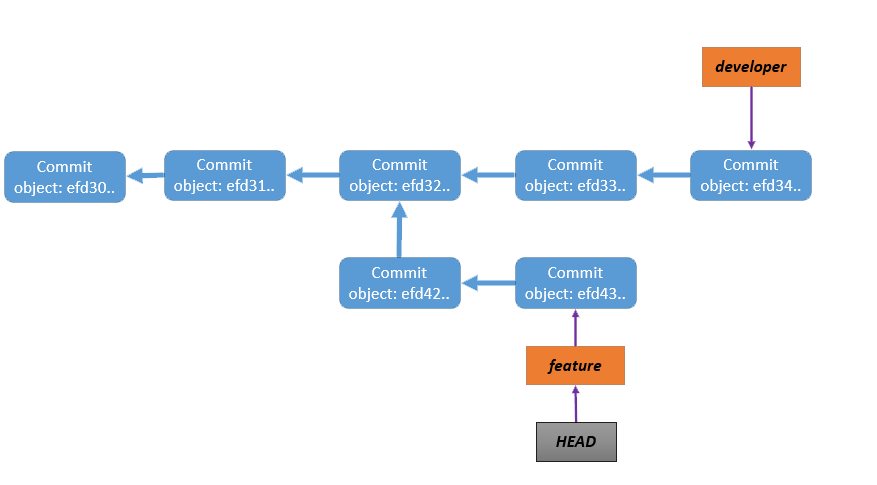
git的分支管理,其实就是在维护一个提交对象的链表。当我们要创建一个分支时,只需要记录一个指向当前版本的引用(它不像Subversion那样是对整个当前版本的拷贝),只要有这个引用就可以遍历所有我们需要的版本。git分支的创建非常轻量、灵活,并切换分支也会非常方便,只需要用git checkout <branchname>命令就可以切换到指定的分支,git要做的只是将HEAD指针指向我们所要checkout分支的最新版本上(就是修改HEAD文件和refs/heads/branchname文件中的版本号)。
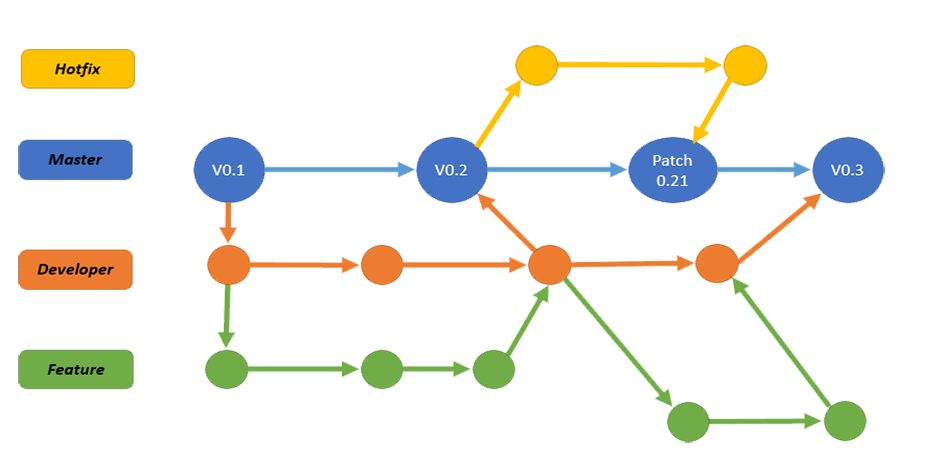
git创建分支固然非常方便,但是仍然需要设定一个好的规则以便团队的合作和分支的管理。下面简单的介绍下常规建分支的规则,当然你也可以根据自己的项目和工作方式进行调整。一般情况我们会有以下几个分支:
-
master:默认情况我们init一个代码库,git会自动创建一个master分支,在项目发布时我将developer分支的代码merge到master上并打上tag,表示一个milestone结束。 -
developer:是所有开发人员共享的分支,这个分支要确保功能的基本稳定,因为它会影响团队的开发和协作。通常我们会对这个分支进行CI/CD(持续集成/持续部署)。 -
feature:为了避免非相关功能的相互影响,我们一般会为独立的功能建立相应的分支,功能完成后将代码merge回developer。 -
hotfix:我们在这个分支上统一的修复项目发布后出现的问题,并在时机成熟时将这个分支合并到master,发布一个patch。
下图描述了具体创建branch的工作流
5. 容易混淆的命令Common Command
git fetch vs git pull
-
git fetch将远程的版本数据拿到本地。 -
git pull不仅将远程的版本数据拿到本地,还对工作区、暂存去以及远程版本数据进行merge。
本质上git pull就是git fetch + git merge,git pull会直接和当前本地版本merge,从而导致一些我们不希望的结果。那么先git fetch,然后根据具体问题决定如何merge可能是更安全的方法。当然在条件明确的条件下,直接使用git pull更加高效。
git rebase vs git merge
-
git merge会在目标分支上生成新的提交对象,用来保存合并后的版本内容。而且两个分支的提交对象被保留。 -
git rebase它会删除从分支的提交对象,然后在目标分支上生成一系列经过处理的提交对象。
从图中我们看到git rebase会新建V3’和V5‘两个提交对象,它们是由git处理合并后的对象,而V3和V5节点会被删除。而git merge则保留了分支的所有信息。
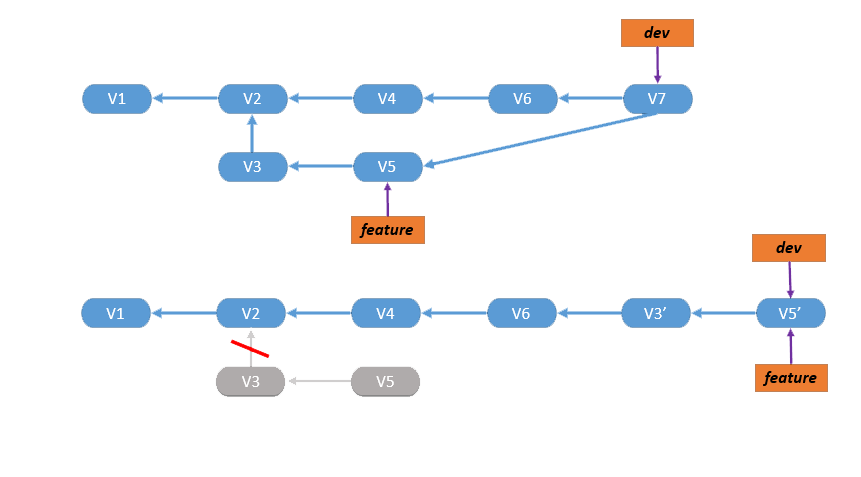
git rebase可以让版本库的分支记录更加整洁,但是和git merge相比它会改变提交代码历史,不利版本回溯和问题定位,而且如果有人在我们git rebase之前的分支上进行编辑,那么等到它merge代码时,我们可以想象他那一脸迷茫的表情。所以我们需要根据具体情况适时的选择git merge和git rebase。
git reset vs git checkout vs git revert
git reset和git checkout在概念上并不会产生很大的混淆,主要的问题还是在操作区域上。
-
git reset三个参数表示操作的三个区域。git reset -soft它会将本地仓库代码reset到指定的版本,而暂存区和工作区保持不变。git reset -mix是重置本地仓库和暂存区,工作区保持不变。git reset -hard的杀伤力比较大,它会重置三个区域的代码,一旦失误就不能恢复。 -
git checkout <branchname>其实和git reset -hard一样会重置工作区和暂存区,但是它不会重置本地历史,所以我们可以随时恢复到任何版本。如果我们只是git checkout filename那么git会以暂存区的数据来重置工作区。 -
git revert可以通过新建一个新的提交来撤销之前的某一个提交,而且此前的提交记录都会被保留。
后记
俗话说工欲善其事必先利其器,利其器我们不能仅仅停留在选择工具和使用工具上,如果适当的了解一些基本的原理会让我们在使用工具时更加事倍功半。